
We Measure the Evidence. You Make the Call. Here’s Why.
We Measure the Evidence. You Make the Call. Here’s Why. We often receive feedback from people who share a common goal: improving animal welfare as much as possible. When feedback
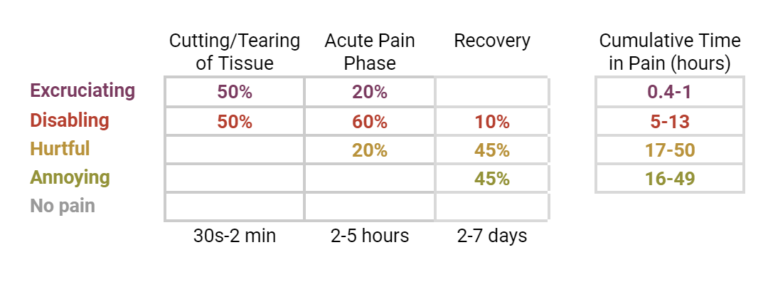
We Measure the Evidence. You Make the Call. Here’s Why. We often receive feedback from people who share a common goal: improving animal welfare as much as possible. When feedback

The Scarcity of Trust in the Age of AI: Why Human Expertise Anchors the Welfare Footprint Wladimir J. Alonso In a recent analysis, Nate B. Jones, a sharp observer of

The Gift of Clarity: making sense of animal welfare with the Welfare Footprint Framework Wladimir J Alonso, Cynthia Schuck-Paim As the year winds down, many of us find ourselves reflecting

